이번에는 HAVING 절에 대해 정리해보겠습니다.
이 절만 정리하면 SELECT => FROM => WHERE => GROUP BY => HAVING => ORDER BY 순서 모두를 살펴보게 되겠네요 :)
그럼 한번 살펴보겠습니다.
먼저 아래 예시를 보겠습니다.
emp 테이블에서 각 부서의 직책별로 급여의 평균이 2000이상인 행만 출력하는 쿼리를 작성하세요.
밑에 답을 보시기 전에 한번 작성해 보시길 추천합니다.
SELECT deptno, job, avg(sal)
FROM emp
WHERE avg(sal) >= 2000
GROUP BY deptno, job
ORDER BY deptno, job;
이렇게 작성하신분들은 왜 안되나 싶을겁니다.
상태 보니까 아무리봐도 맞는데 말입니다.

나온 오류를 읽어볼까요?
group 펑션은 여기서 사용될 수 없습니다. 랍니다.
그 여기가 어딘가 해서 보니 where절이네요?
왜 못쓸까요? 이는 밑에서 다루기로 하고, 이를 해결하기 위해서는 HAVING절을 이용하면 됩니다.
SELECT deptno, job, avg(sal)
FROM emp
GROUP BY deptno, job
HAVING avg(sal) >= 2000
ORDER BY deptno, job;
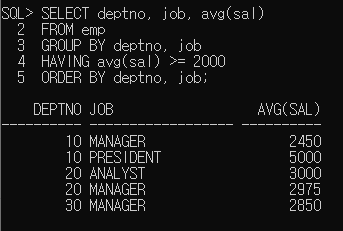
잘 나왔네요.
그러면 왜 그룹 함수는 WHERE절에서 못쓸까요?
여기서 굉장히 중요한 내용이 있습니다.
우리가 데이터베이스를 읽어올 땐, 바로 데이터베이스에 접근하는게 아닙니다.
우리는 먼저 DBMS에게 요청을 보냅니다. 여기서 DBMS는 메모리상에 존재하는 현재 실행중인 서비스입니다.
하드디스크상에 존재하는 파일은, 실행될 때 반드시 메모리로 올라옵니다.
즉, 우리가 사용하는 모든 프로그램은 메모리상에 존재하죠.
아무튼, 이 DBMS가 우리의 요청을 받고 File System, 즉, 하드디스크에 접근합니다.
그 후, 우리가 요청한 데이터를 메모리상에 가져오고 그것을 우리에게 건내줍니다.
정리하자면 이렇습니다.
Program(요청) ↔ [Memory공간]DBMS ↔ [File System 공간]Database
이렇게 간접적으로 데이터베이스에 접근하는 것이죠.
즉, WHERE절은 우리가 요청한 조건을 보고, 해당 조건을 만족하는 데이터를 File System에서 Memory로 올리는 역할을 수행합니다.
우리는 그 메모리에 올라온 값을 가지고 GROUP BY를 하고 HAVING절로 연산하고, ORDER BY절로 정렬하는 것이죠.
데이터베이스에 그룹 함수를 사용할 수 없는 이유, 감이 잡히시나요?
그렇다면 이 문제도 해결해 보세요.
emp 테이블에서 10번, 30번 부서에 소속된 사원들을 대상으로 각 업무별 급여의 평균을 출력하는 쿼리를 작성하세요. 단, 평균 급여의 값이 2000 이상인 행만 '내림차순' 으로 출력하세요.
SELECT job, avg(sal)
FROM emp
WHERE deptno in(10, 30)
GROUP BY job
HAVING avg(sal) >= 2000
ORDER BY avg(sal) desc;


이해가 가시나요?
좀 더 쉽게 설명하자면, 메모리에서 이미 연산이 끝난 데이터들 중에서, HAVING절로 어떤 데이터를 보여줄 것인지를 결정합니다.
위 결과를 설명하자면, WHERE절로 File System에 있는 데이터에서
'인덱스'로 10번과 30번 부서 사원들이 파일 시스템에 어떤 위치에 있는지를 파악합니다.
emp 테이블에 있는 전체 사원들 중, 해당 위치를 찾아서 그 '행 데이터'를 메모리상으로 올립니다.
그 후, 올라온 메모리를 가지고 GROUP BY로 업무별로 나누고, HAVING절로 sal의 평균이 2000이상인 데이터를 보여주
기로 결정합니다. 그리고 그것을 ORDER BY로 내림차순 정렬을 하지요.
이 문제도 한번 봅시다.
[WHERE절이 없을 때]
SELECT deptno, job, avg(sal)
FROM emp
GROUP BY deptno, job
HAVING avg(sal) >= 2000
ORDER BY deptno, job;

[WHERE절이 있을 때]
SELECT deptno, job, avg(sal)
FROM emp
WHERE sal <= 3000
GROUP BY deptno, job
HAVING avg(sal) >= 2000
ORDER BY deptno, job;

왜 이렇게 차이가 나는지 이제 이해가 되시나요?
설명하자면 이렇습니다.
[WHERE절이 없을 때]
모든 값에 대해서 HAVING절이 평균 급여가 2000이상인 데이터만 보여주겠다고 합니다.
그 후 GROUP BY 하고 ORDER BY로 정렬해서 보여줍니다.
그 결과 평균 급여가 5000인 데이터가 나왔습니다.
[WHERE절이 있을 때]
WHERE절이 File System에서 sal 값이 3000 이하인 값을을 찾아서 메모리상에 올립니다.
그 후, 메모리상에 올라온 데이터들만 가지고 HAVING => GROUP BY => ORDER BY 절차를 거칩니다.
그래서 결과적으로 평균 급여가 3000 이하인 값들만 나오게 됩니다.
여기까지 HAVING절에 대한 정리였습니다.



