서브쿼리는 SELECT 문을 조건절(WHERE)에 넣어줄 수 있는것을 의미합니다.
즉, 조건을 어떤 쿼리형태로 나타내고, 최종적으로 인출하는 값을 표기하는 부분이 메인 쿼리가 되겠습니다.
서브 쿼리는
1) 단일 행 서브 쿼리
2) 다중 행 서브 쿼리
위 두 가지로 나눠집니다.
하나하나 정리해보겠습니다.
해당 글에서는 emp 테이블을 활용하여 정리하였습니다.
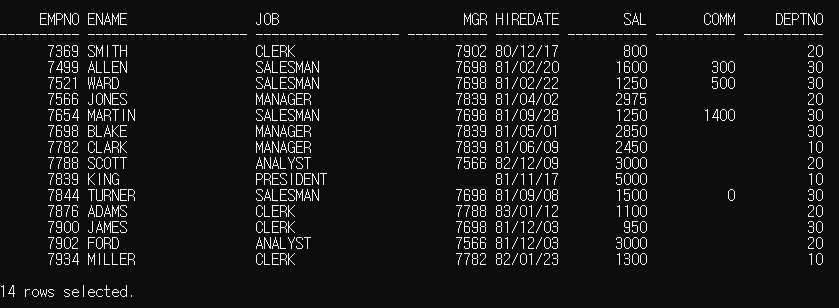
1. 단일 행 서브 쿼리
우리가 어떤 쿼리를 작성할 때, 그룹 함수(SUM, AVG, MAX, MIN ,COUNT) 를 이용하면 단 하나의 실행결과를 얻을 수 있습니다.
예를 들어 이런식으로 말이죠.
SELECT sum(sal)
FROM emp;

이것을 이용한게 단일 행 서브쿼리입니다.
무슨 말인지 아래 예시와 함께 설명드리겠습니다.
JONES 사원보다 더 많은 급여를 받는 사원의 사번, 이름, 급여를 출력하는 쿼리를 작성하세요.
emp 테이블을 볼까요?
JONES 사원의 급여정보를 보겠습니다.
SELECT sal
FROM emp
WHERE ename = 'JONES';

WHERE절을 이용하여 사원 이름(ename)이 'JONES' 인 조건을 활용하였습니다.
JONES 사원은 급여가 2975네요.
만약 우리가 JONES 사원의 급여를 알고 있다면, 위 문제를 단일 행 서브쿼리 없이 위 문제의 답을 해결할 수 있습니다.
SELECT empno, ename, sal
FROM emp
WHERE sal > 2975;
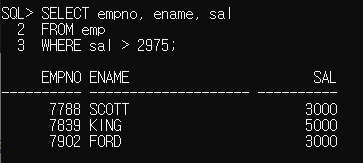
그런데 위 결과는 정말 JONES 사원의 급여를 알고 있기 때문에 WHERE절로 바로 찾을 수 있죠.
하지만 일반적인 상황에서는 값을 알지 못할겁니다. 직접 찾아야 하죠.
위 두가지 스텝을 밟아가며 값을 찾아낼 수 있겠지만, 번거롭죠.
이럴 때, 위 하나의 값을 가지고 단일 행 서브 쿼리를 작성합니다.
또한, 단일 행 연산자를 사용하죠. (<, > ,=, <= 등등..)
SELECT empno, ename, sal
FROM emp
WHERE sal > ???;
위 문제를 해결하기위해서 저 물음표에 무엇이 들어가야할까요?
SELECT sal
FROM emp
WHERE sal > SELECT sal FROM emp WHERE ename = 'JONES';
맨 위에서 찾았던 쿼리가 들어가면 되겠죠.
즉, 'JONES 사원의 급여'가 서브 쿼리,
'더 많은 급여를 받는 사원의 사번, 이름, 급여를 출력' 이 메인 쿼리가 되는 것입니다.
이렇게 적으면 단일 행 서브 쿼리는 끝입니다.
이대로 실행하면....오류입니다!!!
단일 행 서브 쿼리 사용 시 주의 사항입니다.
반드시, 서브 쿼리는 괄호 안에다가 써야 합니다.
아래와 같이 말이죠.
SELECT sal
FROM emp
WHERE sal > (SELECT sal FROM emp WHERE ename = 'JONES');

결과도 위와 같이 나온것을 볼 수 있습니다.
2. 다중 행 서브 쿼리
만약 서브 쿼리의 값이 하나가 아닌, 하나 이상의 결과가 나온다면 어떻게 될까요?
또 그것을 단일 행 서브 쿼리 처럼 사용한다면, 어떻게 될까요?
아래는 각 부서별로 급여의 평균을 출력하는 쿼리입니다.
SELECT avg(sal)
FROM emp
GROUP BY deptno;

이런식으로 값이 하나가 아닌, 하나 이상의 값이 있습니다.
이를 단일 행 서브 쿼리에 사용하면
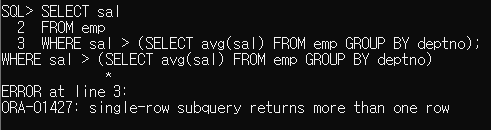
'Single-row subquery returns more than one row' 라는 오류가 납니다.
행이 하나 이상이라면서 뭐라 하는 오류죠.
이처럼 값이 여러개일 경우에는 다중 행 서브 쿼리를 이용해야 합니다.
다중 행 서브 쿼리는 다중 행 연산자(Multiple row Operator)가 와야하는데
1) IN 연산자
2) ANY 연산자
3) ALL 연산자
4) EXISTS
이렇게 네 가지가 있습니다.
1) IN 연산자
IN연산자는 '여러 값 중 하나와 같다'
즉, 메인 쿼리의 데이터가 서브 쿼리의 결과 중 하나라도 일치한 데이터가 있다면 true라는 뜻입니다.
OR 비교연산자와 같죠.
10번 부서 사원들의 급여와 같은 급여를 받는 사원의 이름과 급여를 조회하는 쿼리를 작성하세요.
위와 같은 문제가 있다고 가정합니다.
위에서 '10번 부서 사원들의 급여' 가 조건이 되겠죠.
즉, 서브 쿼리가 됩니다.
그리고 최종 결과는 '같은 급여를 받는 사원의 이름과 급여' 가 나오는 것입니다.
즉, 메인 쿼리가 됩니다.
이처럼, 뭐가 서브 쿼리이고 메인 쿼리인지, 조건이 뭐고 최종 결과가 무엇인지를 파악하는게 우선입니다.
먼저 '10번 부서 사원들의 급여' 를 조회해볼까요?
SELECT sal
FROM emp
WHERE deptno = 10;
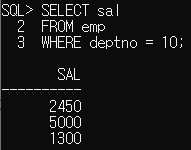
10번 부서에는 총 3명이 있나봅니다. 3개의 결과가 나왔네요.
그러면 이제 메인 쿼리 '같은 급여를 받는 사원의 이름과 급여' 를 작성해 봅시다.
SELECT ename, sal
FROM emp
WHERE sal .... 다음은?
위 서브 쿼리의 결과를 보면 (2450, 5000, 1300) 세개의 결과가 있습니다.
만약, sal이 (2450, 5000, 1300) 안에 있는것과 같다면, 그 사원의 이름과 급여를 출력해주면 되겠죠.
이를 다시 표현하면, sal IN (2450, 5000, 1300)이 되고
(2450, 5000, 1300) 라는 결과는 위 서브 쿼리를 작성하면 되겠죠.
그대로 갖다 붙여봅니다.
SELECT ename, sal
FROM emp
WHERE sal IN (SELECT sal FROM emp WHERE deptno = 10);
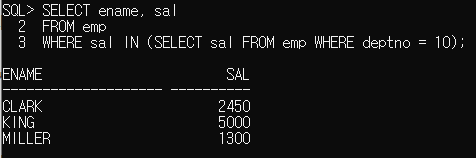
위 세 사원이 10번 부서의 급여와 같나보네요.
[NULL 값을 만나게 된다면?]
아래 문제도 해결해 봅시다.
다른 직원의 상관인 직원들의 사번, 이름, 급여를 조회하는 쿼리를 작성하세요.
서브 쿼리는 무엇이며
메인 쿼리는 무엇인가요?
서브 쿼리는 '다른 직원의 상관' 이 되겠죠.
단, emp 테이블에는 '상관의 번호'만 있음을 주의하세요.
메인 쿼리는, 그런 직원들의 '사번, 이름, 급여를 조회' 하는것이 되겠죠.
따로따로 작성해 봅시다.
먼저 서브 쿼리입니다.
SELECT mgr
FROM emp;
간단하죠? 상관(Manager)만 조회하면 되니까요.
메인 쿼리입니다.
SELECT empno, ename, sal
FROM emp
WHERE empno IN (상관의 사원번호.)
바로 위 두개의 쿼리를 적용해 봅시다.
SELECT empno, ename, sal
FROM emp
WHERE empno IN (SELECT mgr FROM emp);
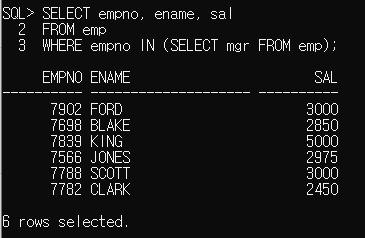
총 6명이 상관을 담당하고 있네요.
그러면 반대로
다른 직원의 상관이 아닌 직원들의 사번, 이름, 급여를 조회하는 쿼리를 작성하세요.
위에서는 IN 연산자를 써서 'IN 안의 값이 일치하다면?' 이란 조건을 명시했습니다.
그러면 위 문제는, 값이 일치하지 않는다면? = 안에 값이 없다면? 이 되겠죠.
고로 IN이 아닌 NOT IN을 사용합니다.
추가로 NOT 연산자를 사용하는 것이죠.
서브 쿼리, 메인 쿼리 나눌 필요 없이 바로 확인해보겠습니다.
SELECT empno, ename, sal
FROM emp
WHERE empno NOT IN (SELECT mgr FROM emp);

결과는 없네요!!
모든 직원이 전부 상관의 역할을 담당하고 있나봅니다!
.... 그럴리가 없죠?
뭔가 문제가 있어보입니다.
당장 맨 위에 SMITH 사원을 봐도 mgr 컬럼에 있지 않습니다.
즉, 상관이 아닙니다.
왜 결과가 나오지 않는 것일까요?
그 이유는 mgr 결과를 봐주세요.
중간에 NULL 값이 존재하는것을 볼 수 있습니다.
NOT IN을 써서 값을 하나하나 비교하면서 보니까, 다른 사원들은 비교가 되면서 잘 나아가다가
NULL 값을 만나 종속되면서 연산이 되지 않게 됩니다.
1 + NULL 값은 NULL값이죠. 값이 없습니다.
따라서 위 NULL 값 때문에 결과가 나오지 않는 것입니다.
그러면 위 문제를 해결하기 위해선, NULL 값을 다른 값으로 대체 하거나, 아예 연산에 포함하지 말아야죠.
대체하기엔 문자형이니 '포함하지 않는' 방식을 택하겠습니다.
먼저 mgr컬럼에서 null 값만 빼고 mgr 값을 출력하기 위해선 IS NOT NULL 을 사용해야죠.
SELECT DISTINCT mgr
FROM emp
WHERE mgr IS NOT NULL;

저는 DISTINCT 를 써서 중복되는 값을 제거 했습니다.
꼭 그러지 않아도 결과는 같습니다.
그러면 이제 위 쿼리를 가지고 아까 그 문제를 해결해 볼까요?
SELECT empno, ename, sal
FROM emp
WHERE empno NOT IN (SELECT DISTINCT mgr FROM emp WHERE mgr IS NOT NULL);

이제서야 결과가 제대로 나온것을 볼 수 있습니다.
2) ANY 연산자
ANY 연산자는 서브 쿼리의 결과 값 중 최소한 하나의 값이 조건식에 만족하면, 메인 쿼리 조건의 결과가 true가 됩니다.
이게 무슨말이냐면, 예를들어 서브 쿼리로 어떤 사원들의 급여를 조회한 결과(100, 200, 300)이 나왔다고 가정해봅시다.
그리고 메인 쿼리의 조건은, 어떤 사원의 급여가, 서브쿼리로 나온 결과들 중 하나라도 참이면, 출력합니다.
더 어려우실려나?
예를들어 메인 쿼리와 서브쿼리가 이렇게 있다고 가정합니다.
행1 서브행1
행2
행3 서브행2
행1과 서브행1을 비교합니다. 예를들어 false가 나왔습니다.
행1과 서브행2를 비교합니다. true가 나왔습니다.
==> 결과로 출력합니다.
행2와 서브행1을 비교합니다. false가 나왔습니다.
행2와 서브행2를 비교합니다. false가 나왔습니다.
==> 결과로 나오지 않습니다.
행3과 서브행1을 비교합니다. true가 나왔습니다.
행3과 서브행2를 비교합니다. true가 나왔습니다.
==> 결과로 출력합니다.
이런식으로 결과가 하나라도 true면 결과로 출력하는게 ANY 연산자 입니다.
그러면 아래 예시를 보겠습니다.
세일즈맨 직책의 급여보다 많이 받는 사원의 사원명과 급여를 조회하는 쿼리를 작성하세요.
서브 쿼리는 '세일즈맨 직책의 급여' 가 되겠죠.
메인 쿼리는 '사원의 사원명과 급여를 조회하는데, 조건은 세일즈맨 직책의 급여보다 많이 받는 사원'이 되겠죠.
형식은 IN과 같습니다.
따라서 저는 바로 한번에 적어보겠습니다.
SELECT ename, sal
FROM emp
WHERE sal > ANY (SELECT sal FROM emp WHERE job = 'SALESMAN');

결과가 잘 나왔는지 서브 쿼리 결과를 볼까요?

1600보다 크거나
1250보다 크거나
1250보다 크거나
1500보다 크다면, true가 되겠죠.
따라서 위에 결과를 보시면 전부 다 false가 되는 경우는 없습니다.
그런데 다시보면, 결론적으론 1250보다 큰 경우들이죠?
따라서 이는 단일 행 서브 쿼리로도 작성이 가능합니다.
3) ALL 연산자
이는 ANY 연산자와는 다르게 서브 쿼리의 모든 결과가 조건식에 맞아야만 true가 되는 연산자입니다.
행1 서브행1
행2
행3 서브행2
행1과 서브행1을 비교합니다. 예를들어 false가 나왔습니다.
행1과 서브행2를 비교합니다. true가 나왔습니다.
==> 결과로 나오지 않습니다.
행2와 서브행1을 비교합니다. false가 나왔습니다.
행2와 서브행2를 비교합니다. false가 나왔습니다.
==> 결과로 나오지 않습니다.
행3과 서브행1을 비교합니다. true가 나왔습니다.
행3과 서브행2를 비교합니다. true가 나왔습니다.
==> 결과로 출력합니다.
위 방식을 가져와서 다시 보면, 행1과 서브행1, 2를 비교했을 때, 값이 나오지 않게 되는 것이죠.
위 문제를 가져와서 보겠습니다.
세일즈맨 직책의 급여보다 많이 받는 사원의 사원명과 급여를 조회하는 쿼리를 작성하세요.
SELECT ename, sal
FROM emp
WHERE sal > ALL (SELECT sal FROM emp WHERE job = 'SALESMAN');

ANY를 썼던 쿼리를 그대로 가져와서 ALL로 바꿔서 결과를 보니 결과의 수가 줄었죠.
'SALESMAN'의 급여들을 보겠습니다.
1250, 1500, 1600모두 true가 되는 값들만 나온것을 볼 수 있습니다.
emp 테이블을 보시면 이해가 더 수월하실거 같네요.
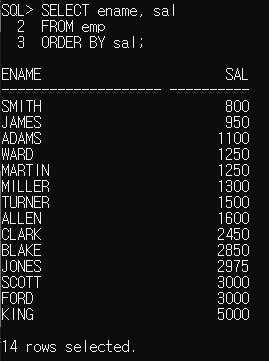
emp 테이블에서 사원명과 급여만 출력해서 오름차순으로 정렬하였습니다.
1600 이상인 사원들이 제대로 나온게 맞다는것을 알 수 있습니다.
4) EXISTS 연산자
이 연산자는 좀 특이합니다.
서브 쿼리에 결과 값이 하나 이상 존재하면 조건식이 모두 true, 아니면 모두 false가 되는 연산자 입니다.
SELECT *
FROM emp
WHERE EXISTS (SELECT dname FROM dept WHERE deptno = 10);
위는 deptno가 10인 사원(dname)이 emp 테이블에 있다면 출력 하라는 의미죠.
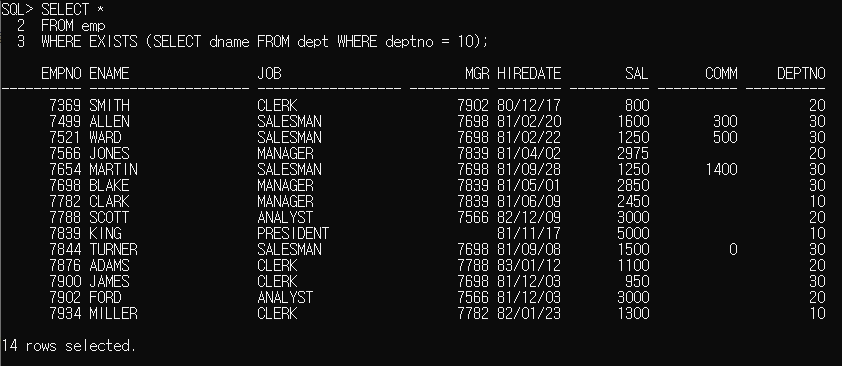
전부 다 나왔죠.
검사하다가 중간에 true가 나오자마자 더 이상의 조건검사는 중단하고 바로 true를 반환해버립니다.
만약 deptno가 50인 사원이 emp 테이블에 있다면?
이라고 실행해보면
SELECT *
FROM emp
WHERE EXISTS (SELECT dname FROM dept WHERE deptno = 50);
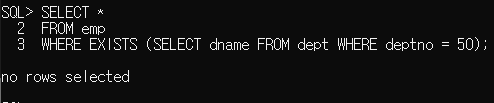
dept 테이블에는 부서 번호 40이 있으니 나오지만, 50부터는 결과가 나오지 않습니다.
따라서 이는 테이블에 특정 행이 있는지 여부에 따라 쿼리 결과가 달라지는 질의에 사용되는 연산자입니다.
예를들어 dept 테이블을 통해 사원들이 속한 부서번호의 정보를 조회하고 싶다고 가정해봅니다.
참고로, emp 테이블에는 40번 부서에 들어간 사원이 없습니다.
하지만 그걸 모른다고 가정해보죠.
SELECT *
FROM dept
WHERE EXISTS (SELECT * FROM emp WHERE emp.deptno = dept.deptno);
기존 JOIN 방식과는 약간 다르죠?
메인 쿼리에 dept 를 명시해줬으니 서브 쿼리에 다시 표시 안해주셔도 됩니다.
이렇게 하면, emp.deptno와 dept.deptno를 비교해서 같으면(공통된 값이 있다면) 바로 결과를 중단하고 해당 dept 테이블의 해당 행을 출력합니다.
emp 테이블에 deptno에 부서번호 10번이 있죠. dept 테이블에 deptno에도 있구요.
여기서 더 이상 검사는 중단하고 행을 출력합니다.
부서번호 20, 30도 마찬가집니다.
원래는 불필요하게 emp 테이블의 행을 하나하나 불러와서 비교하며, detpno이 같다면 출력하고 중복이면 출력하지 않는 불필요한 연산을 하게 되는데, 이를 효율적으로 바꾼것이죠.
즉, 추출하고자 하는 대상만을 FROM절에 놓고, emp 테이블은 체크만 하기위해 EXISTS절에 위치키신 상태입니다. 그러면서 전체 수행속도가 대폭 감소하게 됩니다.
여기까지 서브 쿼리에 관한 내용이였습니다.



